Step-by-Step Video-to-Audio Synthesis via Negative Audio Guidance
ECCV 2026
1Sony AI 2Sony Group Corporation
Abstract
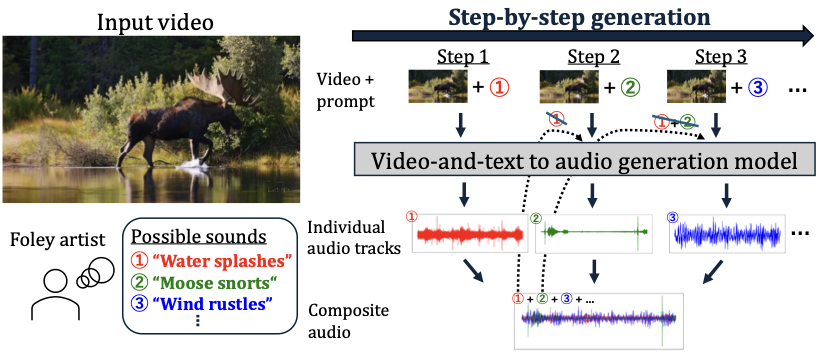
We propose a step-by-step video-to-audio (V2A) generation method that provides finer control over the generation process and more realistic audio synthesis. Inspired by traditional Foley workflows, our approach enables incremental generation of complementary sounds, allowing users to author multiple sound events induced by a video. To avoid the need for costly multi-reference video-audio datasets, each generation step is formulated as a negatively guided V2A process that discourages duplication of sounds already present in previously generated tracks. The guidance model is trained by finetuning a pre-trained V2A model on audio pairs from non-overlapping segments of the same video, encouraging it to leverage acoustic context while remaining visually grounded, and enabling training with standard single-reference audiovisual datasets. Objective and subjective evaluations demonstrate that our method enhances the separability of generated sounds at each step and improves the overall quality of the final composite audio, outperforming existing baselines.
Generated Samples
The linked pages contain videos with audio. All videos have been visually compressed to reduce file size for demonstration purposes and may differ slightly from the actual inputs to the model.
Quick Demo
One representative composite audio example is embedded below for quick comparison. See the other sample links below for detailed individual-track and composite comparisons.
MMAudio
MMAudio + Negative Prompting
Individual Audio Track Comparisons
Per-track comparisons between MMAudio, negative prompting, and our Negative Audio Guidance.
BibTeX
@inproceedings{hayakawa2026step,
title = {Step-by-Step Video-to-Audio Synthesis via Negative Audio Guidance},
author = {Hayakawa, Akio and Ishii, Masato and Shibuya, Takashi and Mitsufuji, Yuki},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2026}
}